
Project Background
This is the introductory project on data modeling in the wide column store NoSQL database Cassandra. For this project I designed a NoSQL database that is able to retrieve information about songs users are listening to. The student is required to design, build, and populate an analytical database from user logs and song data files.
The GitHub for this project is located here: Cassandra-Data-Modeling
Project Datasets
The data set for this project is the same as for the PostgreSQL-Data-Modeling Project. There are two primary datasets for this project. The Song Dataset is a subset of data from the Million Song Dataset and the Log Dataset which is simulated log data for the “Sparkify” company.
Song Dataset
Each song is stored in a different JSON file. An example of the data reads as
{"num_songs": 1, "artist_id": "ARJIE2Y1187B994AB7", "artist_latitude": null, "artist_longitude": null, "artist_location": "", "artist_name": "Line Renaud", "song_id": "SOUPIRU12A6D4FA1E1", "title": "Der Kleine Dompfaff", "duration": 152.92036, "year": 0}
The data schema for this JSON is:
| Field | Data Type |
|---|---|
| num_songs | INT |
| artist_id | VARCHAR |
| artist_latitude | REAL |
| artist_longitude | REAL |
| artist_location | VARCHAR |
| artist_name | VARCHAR |
| song_id | VARCHAR |
| title | VARCHAR |
| duration | NUMERIC |
| year | INT |
Log Dataset
In the Log Dataset each file contains one day’s worth of user logs. This log information is stored in a JSON Line format. In a JSON line file each line is a valid JSON object; however, this means the actual file itself cannot be treated as a JSON file. To avoid errors while reading this file into Python it is recommend to use pandas with the following format:
df = pd.read_json(‘
.json', lines=True)
A sample of this log data in a data frame is shown below:
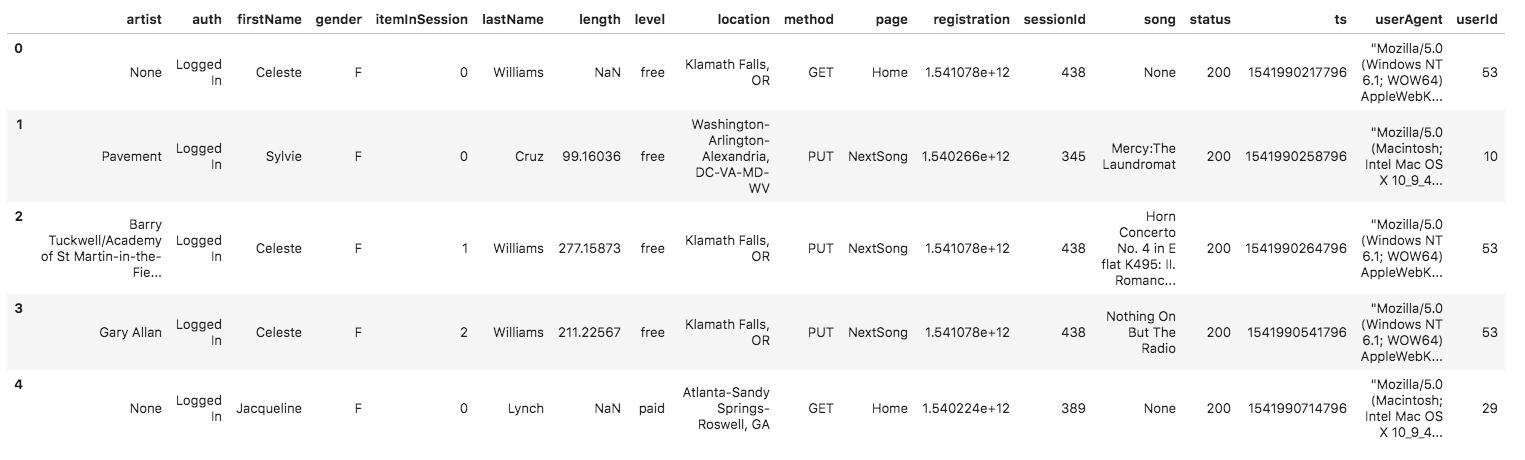
The data schema for the log dataset is:
| Field | Data Type |
|---|---|
| artist | VARCHAR |
| auth | VARCHAR |
| firstName | VARCHAR |
| gender | VARCHAR |
| itemInSession | INT |
| lastName | VARCHAR |
| length | REAL |
| level | VARCHAR |
| location | VARCHAR |
| method | VARCHAR |
| page | VARCHAR |
| registration | NUMERIC |
| sessionId | INT |
| song | VARHCHAR |
| status | INT |
| ts | TIMESTAMP |
| userAgent | VARCHAR |
| userId | INT |
Final Database Schema
The big difference between typical SQL and Cassandra is how tables are designed. In normal SQL you generally have one database structure and a variety of interconnected tables, with multiple queries being able to use this one database structure. In Cassandra that paradigm is flipped. For every query type there is one table. The fields you wish to query against become the Primary Key. There is still a need for unique keys in Cassandra; however, the primary difference is that in Cassandra when a duplicate primary key is inserted into the table, instead of an error the old data will just be overwritten with new data. Therefore, it is critical to think though Primary Keys, Composite Keys, and Clustering Keys.
Below are examples of how a table is built around the desired query type.
Query 1: Table that returns artist, song title, song length during a session and given a specific item in session.
In the Sparkify database there is a session for each time a user logs in and an item in session for each song played while a user is logged into a single session. When these two values are combined they create a unique id which can be used for a composite key. Unlike SQL, in Cassandra it is important to insert the data in order of use, the table below demonstrates the order in which to insert data.
| Field | Data Type | Key |
|---|---|---|
| sessionId | INT | PRIMARY |
| itemInSession | INT | PRIMARY |
| artist | TEXT | |
| song | TEXT | |
| length | FLOAT | |
| firstName | TEXT | |
| gender | TEXT | |
| lastName | TEXT | |
| level | TEXT | |
| location | TEXT | |
| userId | INT |
Now when the query for what artist, song, length, and the location are queried for sessionId 338 and item in session 4 the following return is provided.

Query 2: Create Table, which upon query will return the artist, song and user first name and last name based on userId and sessionId.
For this table the primary key will be composed of the user ID and the session ID with the addition of a composite key of item in session. This item in session will identify the song and the artist for the song the user listened to. Below is a description of the data model and in the order the data is inserted into the table.
| Field | Data Type | Key |
|---|---|---|
| userId | INT | PRIMARY |
| seesionId | INT | PRIMARY |
| itemInSession | INT | COMPOSITE |
| artist | TEXT | |
| song | TEXT | |
| firstName | TEXT | |
| lastName | TEXT | |
| length | FLOAT | |
| gender | TEXT | |
| level | TEXT | |
| location | TEXT |
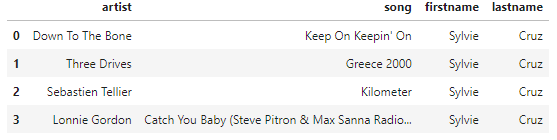
Now when the table is queried for the for the userId=10 and the sessionid=182 the following is returned.
Query 3: Create Table, which upon query will return the first and last name of a user who has listened to a song.
For this table the primary key will be songId and the userId. The songId is the will be queried against, but to make it unique the userId needs to be added to make it a composite key, as such they were designated as the Primary Key. The remaining fields were created in order based upon their usage. For example, the query given asks to return the artist, song title, and user, these are created after the Primary Key fields of sessionID and itemInSession. The data model for the table and the order in which the data is inserted into the table is below.
| Field | Data Type | Key |
|---|---|---|
| song | TEXT | PRIMARY |
| userId | INT | PRIMARY |
| firstName | TEXT | |
| lastName | TEXT | |
| seesionId | INT | |
| itemInSession | INT | |
| artist | TEXT | |
| length | FLOAT | |
| gender | TEXT | |
| level | TEXT | |
| location | TEXT |
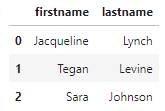
When the table is queries for the song “All Hands Against His Own” the following is returned.
Project Process
For this project the tables needed to be created to reflect the query. Instead of having a single data model that multiple queries run against, there is a data table for each query.
- Determine what query needs to be ran to get the desired result.
- Determine the appropriate primary and composite keys.
- Build the table.
- Insert the data in the order of importance, this will help the processing time when inserting data.
Lessons Learned/Final Thoughts
As my knowledge of databases is based on the relational model, this was an entirely different thought process for me. What I learned most from this lesson was the concept of polyglot persistence, wherein an organization can have multiple databases for the same data. While this seems counterintuitive, it actually makes sense. Instead of having one large database that performs well for some operations but suffers performance issues for others, you can have multiple databases that are designed around the needed applications. While there is a need for a more controls to ensure data assurance this design methodology will result in an approved user experience.
This was a simple project where I learned a great deal. I am no means a Cassandra expert, but I have a solid experience and some decent use case examples.