
Project Background
This is the introductory project in a traditional SQL database. For this project I designed, built, and populated an analytical database from user logs and song data files.
The GitHub for this project is located here: PostgreSQL-Data-Modeling
Project Datasets
There are two primary datasets for this project. The Song Dataset is a subset of data from the Million Song Dataset and the Log Dataset which is simulated log data for the “Sparkify” company.
Song Dataset
Each song is stored in a different JSON file. An exmaple of the data reads as
{"num_songs": 1, "artist_id": "ARJIE2Y1187B994AB7", "artist_latitude": null, "artist_longitude": null, "artist_location": "", "artist_name": "Line Renaud", "song_id": "SOUPIRU12A6D4FA1E1", "title": "Der Kleine Dompfaff", "duration": 152.92036, "year": 0}
The data schema for this JSON is:
| Field | Data Type |
|---|---|
| num_songs | INT |
| artist_id | VARCHAR |
| artist_latitude | REAL |
| artist_longitude | REAL |
| artist_location | VARCHAR |
| artist_name | VARCHAR |
| song_id | VARCHAR |
| title | VARCHAR |
| duration | NUMERIC |
| year | INT |
Log Dataset
In the Log Dataset each file contains one day’s worth of user logs. This log information is stored in a JSON Line format. In a JSON line file each line is a valid JSON object; however, this means the actual file itself cannot be treated as a JSON file. To avoid errors while reading this file into Python it is recommend to use pandas with the following format:
df = pd.read_json(‘
.json', lines=True)
A sample of this log data in a dataframe is shown below:
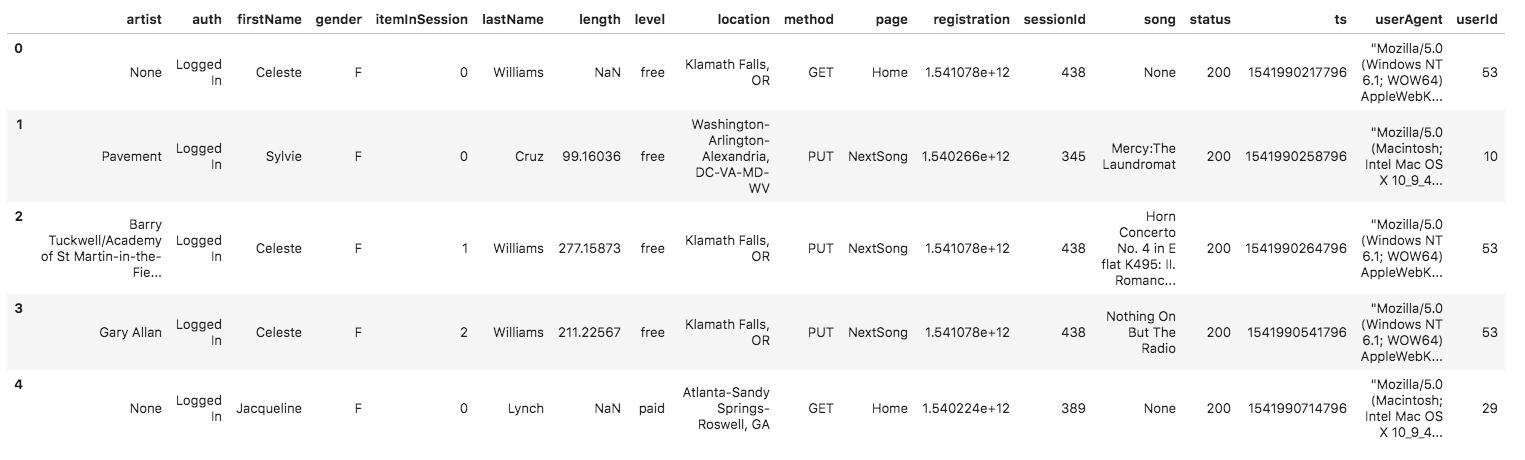
The data schema for the log dataset is:
| Field | Data Type |
|---|---|
| artist | VARCHAR |
| auth | VARCHAR |
| firstName | VARCHAR |
| gender | VARCHAR |
| itemInSession | INT |
| lastName | VARCHAR |
| length | REAL |
| level | VARCHAR |
| location | VARCHAR |
| method | VARCHAR |
| page | VARCHAR |
| registration | NUMERIC |
| sessionId | INT |
| song | VARHCHAR |
| status | INT |
| ts | TIMESTAMP |
| userAgent | VARCHAR |
| userId | INT |
Final Database Schema
To enable fast returns on the analytic queries the project database design used a star schema. By using the star schema, the database will likely be fully 3NF, but the tradeoff is queries will return faster. As the project dataset is small and the entries are being inserted via a python script the redundancy in the database will have little impact on the actual operation.
The star schema database has five tables: songplays, users, songs, artists, and time. The database ERD is shown below:
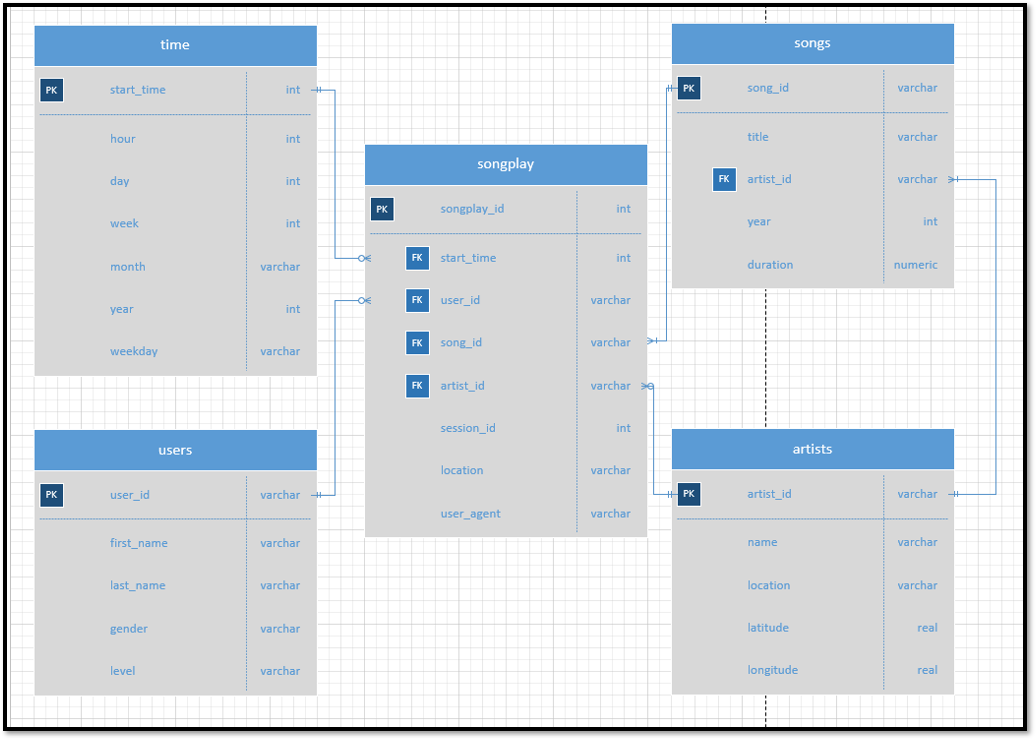
The time table which contains:
| Field | Data Type | Key |
|---|---|---|
| start_time | INT | Primary |
| hour | INT | |
| day | INT | |
| week | INT | |
| month | INT | |
| year | INT | |
| weekday | INT |
The users table which contains:
| Field | Data Type | Key |
|---|---|---|
| user_id | VARCHAR | Primary |
| first_name | VARCHAR | |
| last_name | VARCHAR | |
| gender | VARCHAR | |
| level | VARCHAR |
The songs table which contains:
| Field | Data Type | Key |
|---|---|---|
| song_id | VARCHAR | Primary |
| title | VARCHAR | |
| artist_id | VARCHAR | Foreign Key |
| year | INT | |
| duration | NUMERIC |
The artists table which contains:
| Field | Data Type | Key |
|---|---|---|
| artist_id | VARCHAR | Primary |
| name | VARCHAR | |
| location | VARCHAR | Foreign Key |
| latitude | real | |
| longitude | real |
The songplay table which contains:
| Field | Data Type | Key |
|---|---|---|
| songplay_id | INT | Primary |
| start_time | INT | Foreign Key |
| user_id | VARCHAR | Foreign Key |
| song_id | VARCHAR | Foreign Key |
| artist_id | VARCHAR | Foreign Key |
| session_id | INT | |
| location | VARCHAR | |
| user_agent | VARCHAR |
Project Process
This project required the creation of the tables along with the insert queries from the JSON data into the appropriate table.
- The DROP TABLE query was made for each of the tables. This would ensure the table was deleted from the database before the same table was created. This is important if any changes were made to the table design.
- The CREATE TABLE query was used for each table and dictated the data type and any constraints such as Primary Key and Foreign Key.
- Data was inserted for the tables.
Data Test
The following quires were conducted to ensure the data had been inserted into the tables correctly.
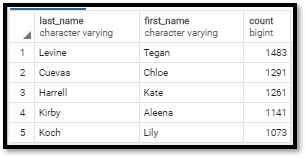
TOP FIVE USERS
This query returned the top five users based upon instances.
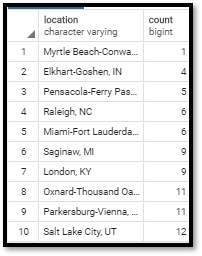
Bottom Ten Locations
This query returned the ten locations that has the lowest number of logged users.
Lessons Learned/Final Thoughts
I have worked with SQL databases for many years and part of my Master’s program involved an in-depth class on relational theory and Oracle SQL databases, so the SQL basics of this class were not difficult. Perhaps the thing I learned the most was to be willing to break away from third normal form when moving data from a record-based system to an analytic based system. While I am still not entirely comfortable with this the though the speed impacts are hard to argue against. For me the key would be an automated process to ensure values are keeping some type of consistency.
Overall, this was a fun project and helped brush off the dust on my SQL skills.